
SpiNNcloud is the only solution supporting real-time AI computing at a large-scale, which is essential to create cognitive cities and drive the third-wave of AI. The SpiNNcloud computational power not only approaches the Human Brain, but it also leverages research from the EU’s Human Brain Project (HBP) to provide unique brain-like capabilities in every single industry requiring real-time AI.
Biological Comparison
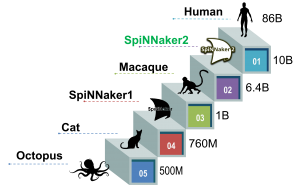
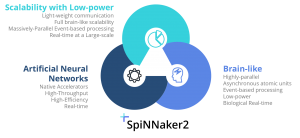
The Human Brain is the most complex known structure in the universe. It not only excels at performing real-time computing, but it also achieves it with a remarkable energy efficiency. For these reasons, future systems saturated by Moore’s law need to search for brain inspiration if they are to maintain a competitive advantage. Our SpiNNaker2 chip, and its system level, named SpiNNcloud, is designed with two main principles. Its brain-like parallel topology and event-based operation together with its native AI accelerators provide a massively-parallel silicon brain, whereas its highly-tailored energy efficiency schemes inspired by the on-demand biological hyperactivation, ensure a very low-power operation. This is key to provide powerful systems without going against the requirements of a sustainable world.
In terms of the biologically inspired neural networks that can be implemented in the SpiNNcloud system, its number of neurons approach the Human level with a vast number of 10 billion neurons. In addition to that, our system integrates as many transistors in the SpiNNcloud machine as synapses in the Human brain (average of 1014-1015). Our native AI accelerators can support 100 synaptic transmissions per second per synapse of a Human brain. These brain-like capabilities, together with highly-tailored sparsity-aware algorithms, and massively-parallel computation capabilities, makes SpiNNcloud a unique system with an unprecedented large-scale operation at real-time. SpiNNcloud is the only real-time system world-wide approaching the right order of magnitude of the Human brain.
Unique Joint Approach
Our system is not a traditional Neuromorphic computer. We offer a unique joint approach between Neuromorphics, Deep Learning, and Symbolic AI for a real-time, low-latency, and energy-efficient cognitive AI platform. The native support of these three components are crucial to drive the third-wave of AI. The brain-like properties ensure efficiency through event-based sparse processing in real-time, the Deep Learning capabilities provide localized statistical-based networks to fulfill specialized tasks, and the Symbolic layers grant a holistic integration of all the individual capabilities to enable general intelligence frameworks. This joint approach is unprecedented, and its full scope of capabilities were not currently offered in the open market of AI hardware. Our system is the only real-time AI cloud, powering instantaneous robotics control, sensing, prediction and insights, enabling the most intelligent and capable robots, and the most effective cognitive services.
Our Topology
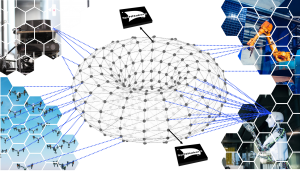
As presented in the SpiNNaker2 chip-level description, our system operates with a light-weight network on-chip and on-demand processing triggered by incoming or outcoming data streams. The system has a massively-parallel topology allowing concurrent processing from multiple actuators and sensor streams in real-time, with a response-time below 1ms.
Our main value proposition is summarized as follows:
- In contrast to traditional High Performance Computing (HPC) systems, the power consumption of our system is proportional to the information being streamed across and processed during operation.
- Our system is holistically fast and efficient. Our individual chips have a state-of-the-art low-power consumption, and maintain a top efficiency for the overall system as well.
- Taking inspiration from the biological Interbout Arousal (IBA) mechanism, our system contains fine granular patented power management to reduce the energy consumption, and unleash the maximum performance only on-demand.
- Contrary to the traditional communication protocols used in HPC systems, our system works with a light-weight scalable communication architecture between its processing elements to support sparsity, event-based processing, and asynchronous execution.
- Our system has native support to perform statistical AI (e.g., Deep Learning), biologically inspired neural networks (e.g., Spiking Neural Networks), and symbolic layers to interconnect holistically localized networks, which are all combined in a unique approach to enable the third-wave of AI.
- As it is the Human brain, our system is inherently parallel and performs real-time computation at an unprecedented large-scale.
- In contrast to traditional HPC systems, our system can scale up beyond 10 million cores, while maintaining its real-time capabilities. This is possible due to its light-weight network topology and to its independent asynchronous atomic units.
- Our system reaches an AI throughput of up to 250 Peta operations per second using an 8-bit format to satisfy the robustness and safety required in critical AI applications (e.g., Automotive).
- Our system is the largest brain-like system and can implement up to 10 billion neurons, getting close to the Human brain number of neurons.
- Our system comes equipped with the most advanced 3D volumetric hologram display to provide an immersive experience into the internal activity taking place in our silicon brain.
Please contact us for more information.
